Long Short-Term Memory (LSTM) is an improved version of Recurrent Neural Network (RNN) designed to capture long-term dependencies in sequential data. It uses a memory cell to store information over time, solving the limitations of traditional RNNs.
This makes it useful for:
- Handles Long Term Dependencies: Remembers information for longer sequences
- Memory Cell: Stores and updates important information over time
- Better than RNN: Overcomes short term memory limitations
- Applications: Used in language translation, speech recognition and time series forecasting
Problem with Long-Term Dependencies in RNN
RNNs are designed to handle sequential data by using a hidden state that stores information from previous steps. However, they struggle to learn long-term dependencies. This happens due to:
- Vanishing Gradient: When training a model over time, the gradients which help the model learn can shrink as they pass through many steps. This makes it hard for the model to learn long-term patterns since earlier information becomes almost irrelevant.
- Exploding Gradient: Sometimes gradients can grow too large causing instability. This makes it difficult for the model to learn properly as the updates to the model become erratic and unpredictable.
LSTM Architecture
LSTM architectures involves the memory cell which is controlled by three gates:
- Input gate: Controls what information is added to the memory cell.
- Forget gate: Determines what information is removed from the memory cell.
- Output gate: Controls what information is output from the memory cell.
This allows LSTM networks to selectively retain or discard information as it flows through the network which allows them to learn long-term dependencies. The network has a hidden state which is like its short-term memory. This memory is updated using the current input, the previous hidden state and the current state of the memory cell.
Working of LSTM
LSTM architecture has a chain structure that contains four neural networks and different memory blocks called cells.
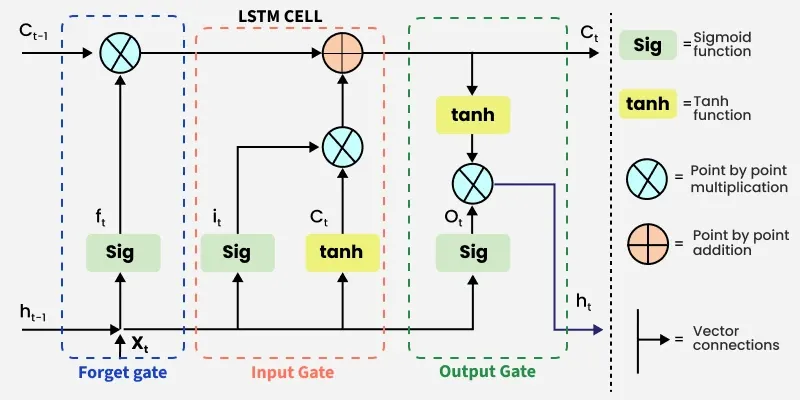
LSTM Model
Information is retained by the cells and the memory manipulations are done by thegates**.** There are three gates:
1. Forget Gate
The forget gate decides which information to keep or remove from the cell state. It uses the current input and previous output applies weights and bias and passes the result through a sigmoid function that outputs values between 0 and 1. Values close to 0 remove information, while values close to 1 retain it.
The equation for the forget gate is:
Where:
- represents the weight matrix associated with the forget gate.
- denotes the concatenation of the current input and the previous hidden state.
- is the bias with the forget gate.
- is the sigmoid activation function.
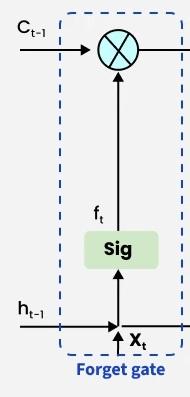
Forget Gate
2. Input gate
The addition of useful information to the cell state is done by the input gate.
- First the information is regulated using the sigmoid function and filter the values to be remembered similar to the forget gate using inputs and .
- Then, a vector is created using tanh function that gives an output from -1 to +1 which contains all the possible values from and .
- At last the values of the vector and the regulated values are multiplied to obtain the useful information.
The equation for the input gate is:
We multiply the previous state by effectively filtering out the information we had decided to ignore earlier. Then we add which represents the new candidate values scaled by how much we decided to update each state value.
where
- denotes element-wise multiplication
- tanh is activation function
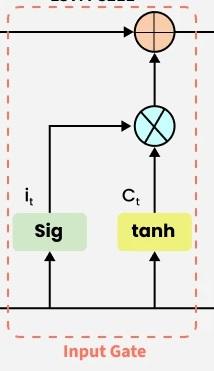
Input Gate
3. Output gate
The output gate is responsible for deciding what part of the current cell state should be sent as the hidden state (output) for this time step. First, the gate uses a sigmoid function to determine which information from the current cell state will be output. This is done using the previous hidden state and the current input :
Next, the current cell state is passed through a tanh activation to scale its values between and . Finally, this transformed cell state is multiplied element-wise with to produce the hidden state :
Here:
- is the output gate activation.
- is the current cell state.
- represents element-wise multiplication.
- is the sigmoid activation function.
This hidden state is then passed to the next time step and can also be used for generating the output of the network.
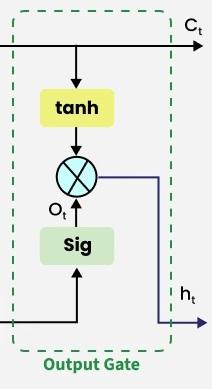
Output Gate
Applications
- Language Modeling: Used in tasks like language modeling, machine translation and text summarization. These networks learn the dependencies between words in a sentence to generate coherent and grammatically correct sentences.
- Speech Recognition: Used in transcribing speech to text and recognizing spoken commands. By learning speech patterns they can match spoken words to corresponding text.
- Time Series Forecasting: Used for predicting stock prices, weather and energy consumption. They learn patterns in time series data to predict future events.
- Anomaly Detection: Used for detecting fraud or network intrusions. These networks can identify patterns in data that deviate drastically and flag them as potential anomalies.
- Recommender Systems: In recommendation tasks like suggesting movies, music and books. They learn user behavior patterns to provide personalized suggestions.
- Video Analysis: Applied in tasks such as object detection, activity recognition and action classification. When combined with Convolutional Neural Networks (CNNs) they help analyze video data and extract useful information.
5 Questions

Quiz Completed Successfully
Your Score:0/5
Accuracy:0%
Article Tags: